深度学习炼丹踩坑
由于时效问题,该文某些代码、技术可能已经过期,请注意!!!本文最后更新于:3 年前
如题
GPU显存
使用GPU进行炼丹的时候,发现了些ghost进程,如图中所示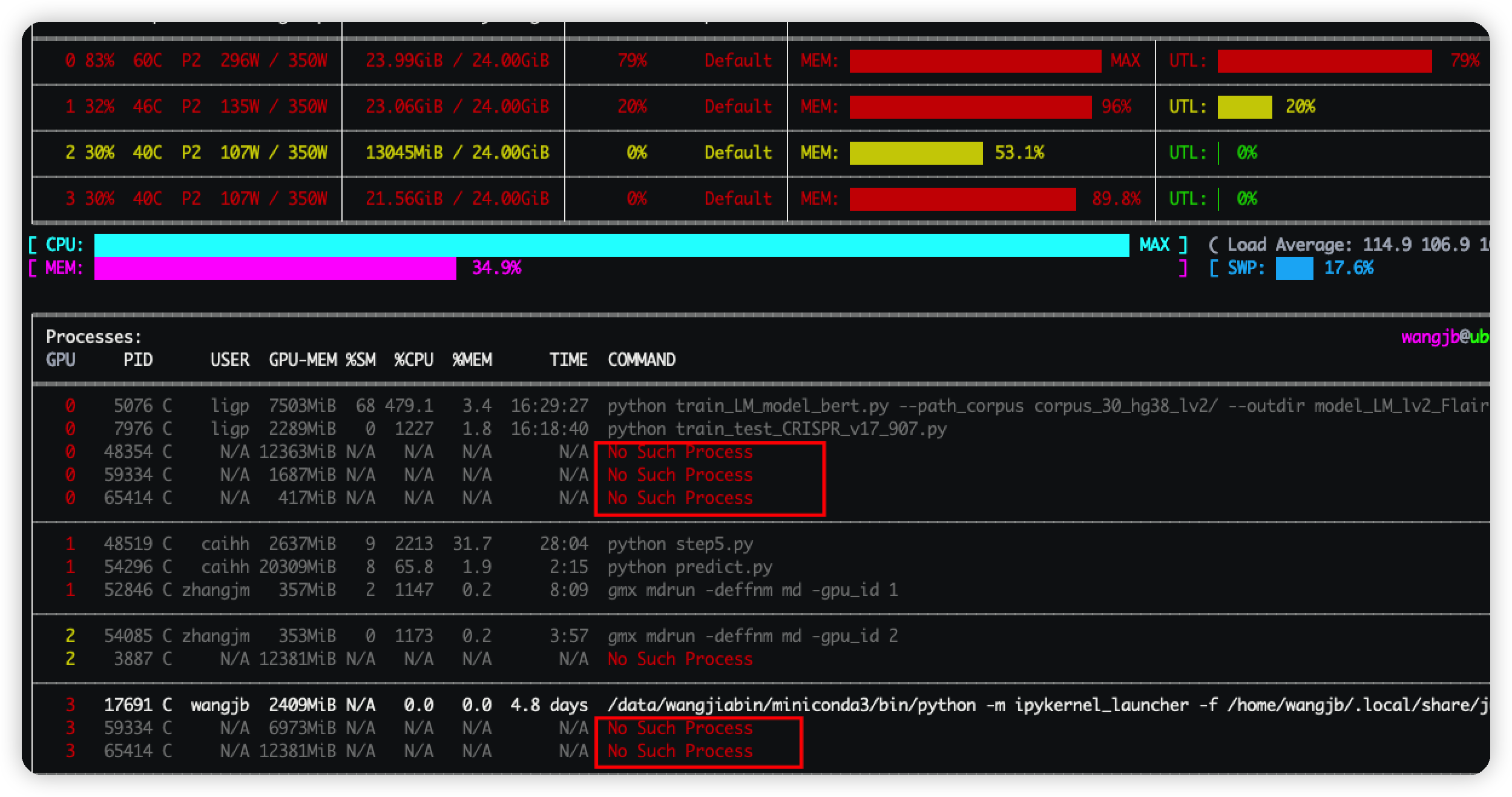
这些进程不仅占用了大量的GPU显存,而且使用 ps 查询该进程的时候竟然都查不到。
好在互联网上查到了解决的办法
1 | |
使用该命令查询出所有在GPU显卡上的进程,然后kill掉已经不存在的进程即可释放显存。
learning rate
在网上找了张图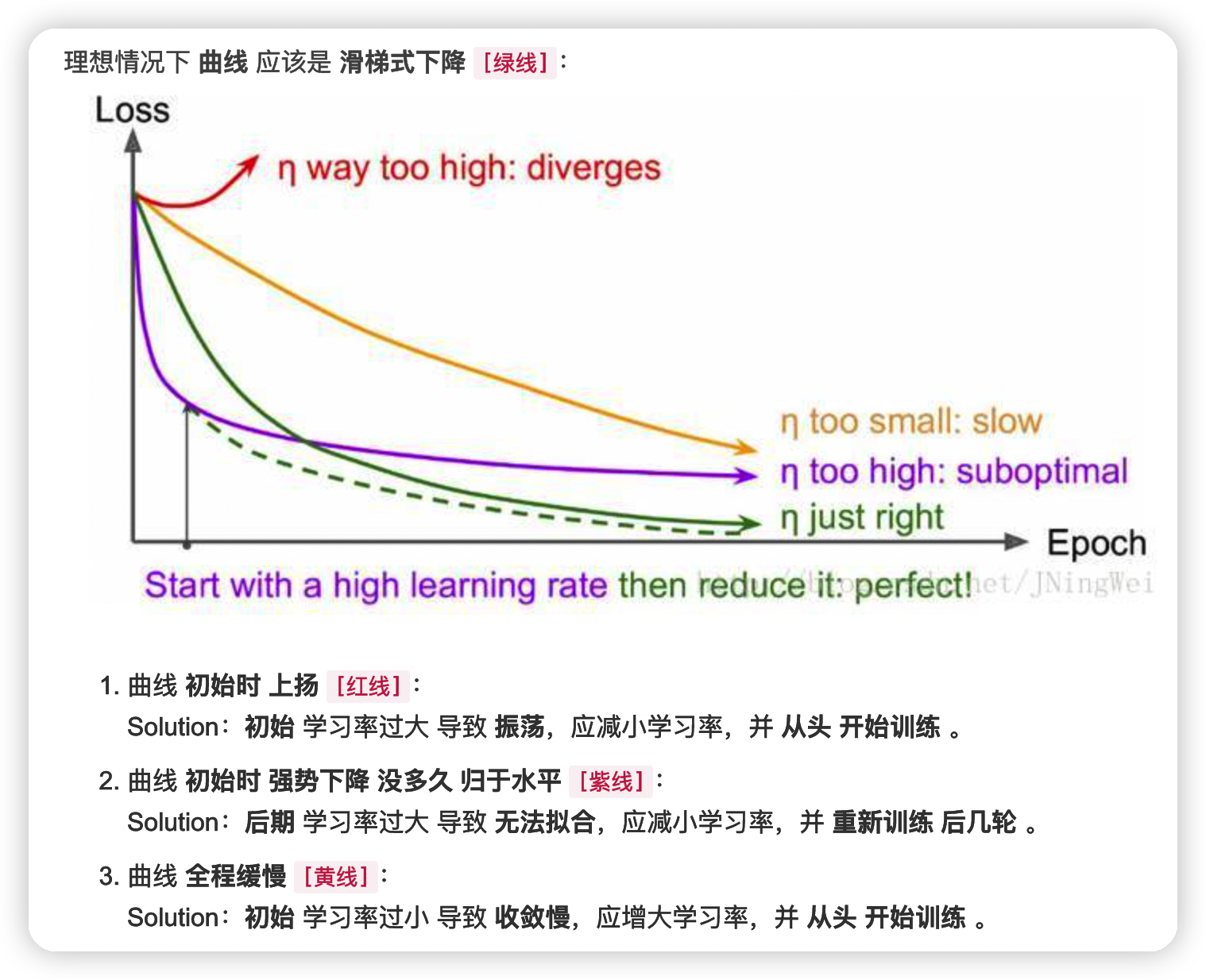
LR在优化算法中更新网络权重的幅度大小,同时也是深度学习中需要调的第一大参数了吧。一般学习率从0.1或0.01开始尝试,如果太大loss会很震荡甚至直接NA,太小了收敛就会很慢。学习率一般要随着训练进行衰减。衰减系数设0.1,0.3,0.5均可,衰减时机,可以是验证集准确率不再上升时,或固定训练多少个周期以后自动进行衰减。当然了也可以一个学习率走到底(不衰减)。
batch size
深度学习中一直都有一些参数有着玄学般的存在,比如 random seed = 42,batch size 设置为 2 的倍数,或者 8 的倍数等等。但是最近有大佬对 batch size 这个玄学问题做了实验,结果呢就是也不用非要按 2 的倍数这样去设置。既然玄学被打破那就随心好了,在GPU显存允许的范围内可以尽量设置大点,这样可以节约不少时间。当然了也不能盲目的使用一个大的batch size,如果模型效果不好,该改还是要改的,毕竟玄学终究是玄学。
optimizer
目前的优化器有 Adagrad, Adadelta, RMSprop, Adam等,这么多该怎么选呢,整体来讲,Adam是最好的选择,也就是像我这样的小白直接无脑 Adam 就好了。大佬请随意。
当然了还有一些其他的参数,比如 weight decay, epoch, drop out 等等,epoch 主要就是训练的轮数,只要没过拟合,loss没收敛,那epoch就只能往大了改。如果过拟合了就可以增加 weight decay, drop out的参数,或者使用其他的正则化或者减少过拟合的方法。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!